第二次作业请在 3 月 12 日上课前交,逾期不再接收!
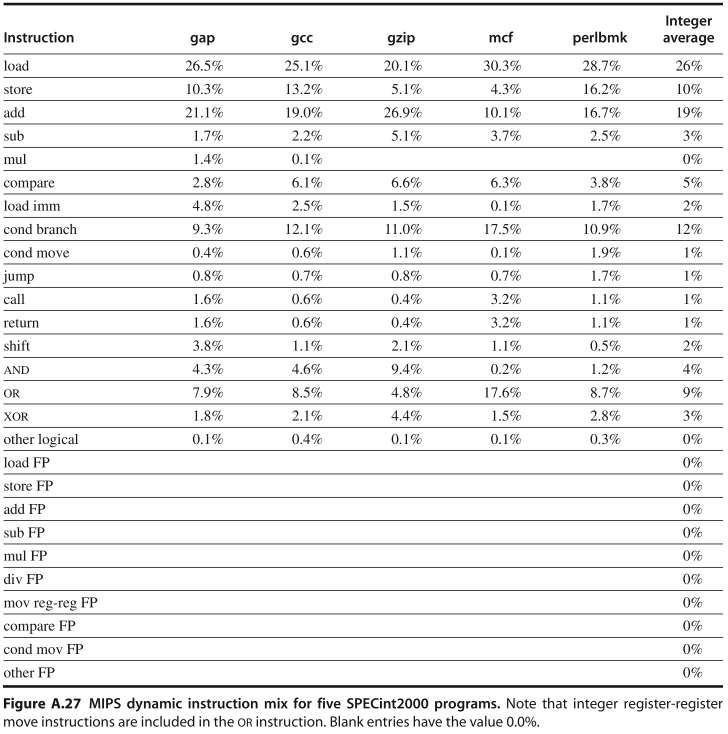
Compute the effective CPI for MIPS using Figure A.27 and the table above. Average the instruction frequencies of gzip and perlbmk to obtain the instruction mix.
Consider the following fragment of C code:
for (i = 0; i <= 100; i++)
{ A[i] = B[i] + C; }
Assume that A and B are arrays of 64-bit integers, and C and i are 64-bit integers. Assume that all data values and their addresses are kept in memory (at addresses 1000, 3000, 5000, and 7000 for A, B, C, and i, respectively) except when they are operated on. Assume that values in registers are lost between itera- tions of the loop.
a. Write the code for MIPS. How many instructions are required dynamically? How many memory-data references will be executed? What is the code size in bytes?
b. Write the code for x86. How many instructions are required dynamically? How many memory-data references will be executed? What is the code size in bytes?
The design of MIPS provides for 32 general-purpose registers and 32 floating-point registers. If registers are good, are more registers bet- ter? List and discuss as many trade-offs as you can that should be considered by instruction set architecture designers examining whether to, and how much to, increase the number of MIPS registers.
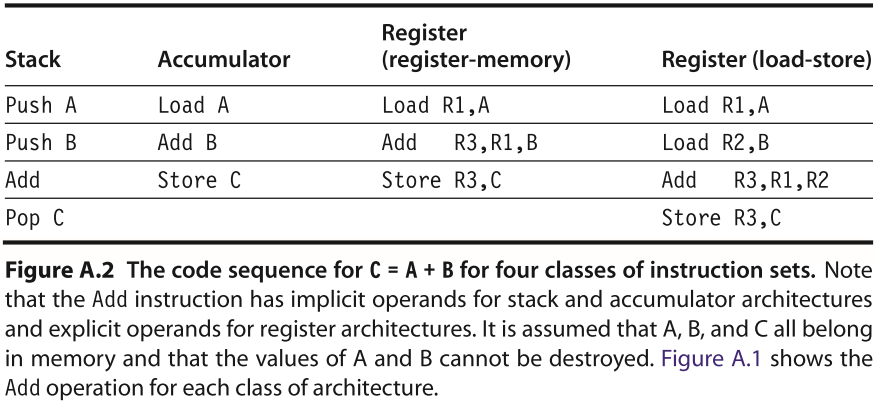
Your task is to compare the memory efficiency of four different styles of instruction set architectures. The architecture styles are
To measure memory efficiency, make the following assumptions about all four instruction sets:
a. Invent your own assembly language mnemonics (Figure A.2 provides a useful sample to generalize), and for each architecture write the best equivalent assembly language code for this high-level language code sequence:
A = B + C;
B = A + C;
D = A – B;
b. Label each instance in your assembly codes for part (a) where a value is loaded from memory after having been loaded once. Also label each instance in your code where the result of one instruction is passed to another instruction as an operand, and further classify these events as involving stor- age within the processor or storage in memory.
c.Assume that the given code sequence is from a small, embedded computer application, such as a microwave oven controller, that uses a 16-bit memory address and data operands. If a load-store architecture is used, assume it has 16 general-purpose registers. For each architecture answer the following questions: How many instruction bytes are fetched? How many bytes of data are transferred from/to memory? Which architecture is most efficient as measured by total memory traffic (code + data)?
d. Now assume a processor with 64-bit memory addresses and data operands. For each architecture answer the questions of part (c). How have the relative merits of the architectures changed for the chosen metrics?
The value represented by the hexadecimal number 434F 4D50 5554 4552 is
to be stored in an aligned 64-bit double word.
a. Using the physical arrangement of the first row in Figure A.5, write the value to be stored using Big Endian byte order. Next, interpret each byte as an ASCII character and below each byte write the corresponding character, forming the character string as it would be stored in Big Endian order.
b. Using the same physical arrangement as in part (a), write the value to be stored using Little Endian byte order, and below each byte write the corresponding ASCII character.
c. What are the hexadecimal values of all misaligned 2-byte words that can be read from the given 64-bit double word when stored in Big Endian byte order?
d. What are the hexadecimal values of all misaligned 4-byte words that can be read from the given 64-bit double word when stored in Little Endian byte order?
{kind=link}
{kind=link}